


A Mild Introduction to Batch Normalization
Picture by Editor | ChatGPT
Introduction
Deep neural networks have drastically advanced through the years, overcoming frequent challenges that come up when coaching these complicated fashions. This evolution has enabled them to resolve more and more troublesome issues successfully.
One of many mechanisms that has confirmed particularly influential within the development of neural network-based fashions is batch normalization. This text gives a mild introduction to this technique, which has turn out to be a regular in lots of fashionable architectures, serving to to enhance mannequin efficiency by stabilizing coaching, dashing up convergence, and extra.
How and Why Batch Normalization Was Born?
Batch normalization is roughly 10 years previous. It was initially proposed by Ioffe and Szegedy of their paper Batch Normalization: Accelerating Deep Community Coaching by Lowering Inside Covariate Shift.
The motivation for its creation stemmed from a number of challenges, together with sluggish coaching processes and saturation points like exploding and vanishing gradients. One explicit problem highlighted within the unique paper is inner covariate shift: in easy phrases, this challenge is expounded to how the distribution of inputs to every layer of neurons retains altering throughout coaching iterations, largely as a result of the learnable parameters (connection weights) within the earlier layers are naturally being up to date throughout your complete coaching course of. These distribution shifts would possibly set off a kind of “rooster and egg” downside, as they power the community to maintain readjusting itself, typically resulting in unduly sluggish and unstable coaching.
How Does it Work?
In response to the aforementioned challenge, batch normalization was proposed as a technique that normalizes the inputs to layers in a neural community, serving to stabilize the coaching course of because it progresses.
In observe, batch normalization entails introducing an extra normalization step earlier than the assigned activation operate is utilized to weighted inputs in such layers, as proven within the diagram beneath.
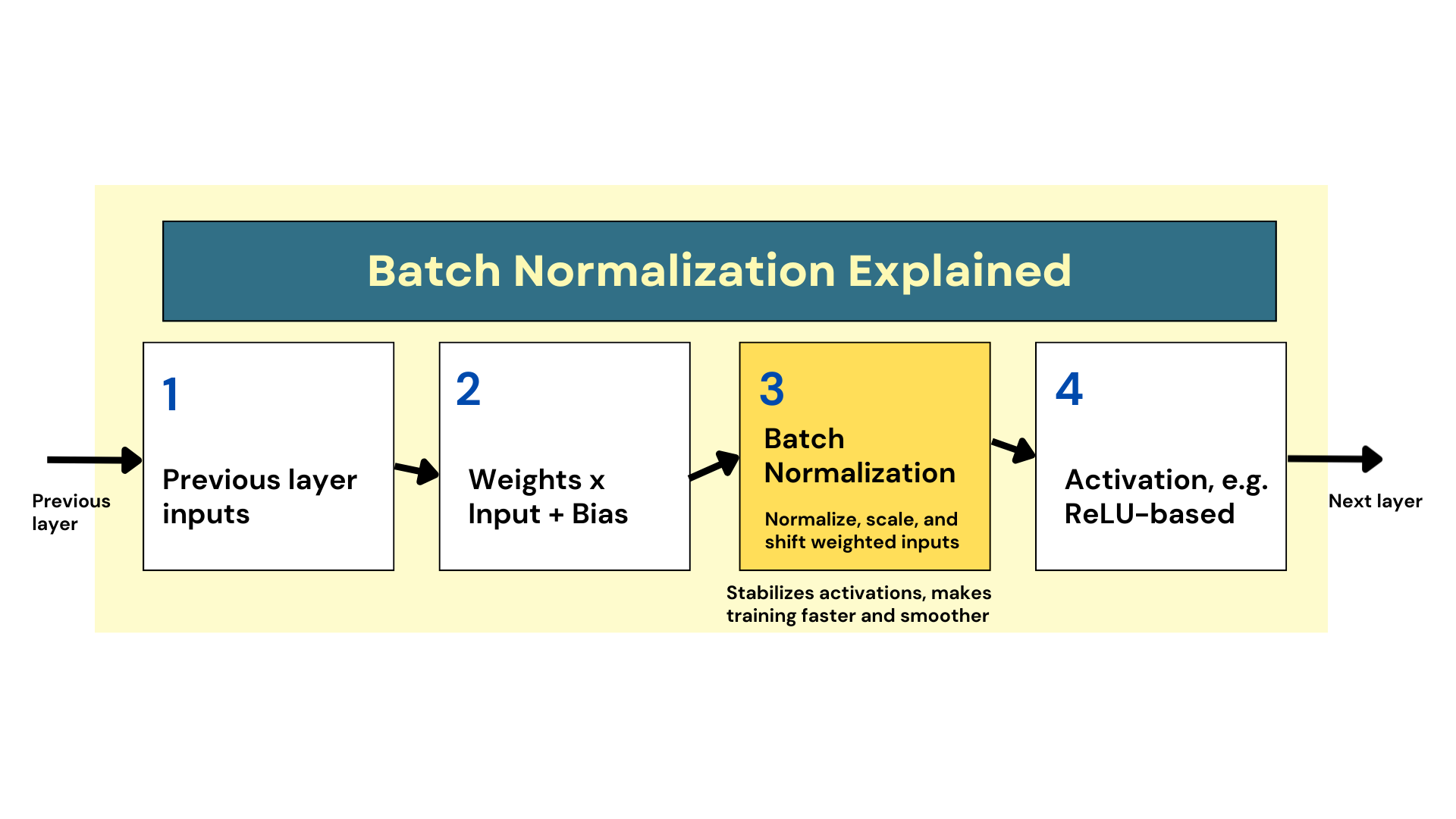
How Batch Normalization Works
Picture by Creator
In its easiest type, the mechanism consists of zero-centering, scaling, and shifting the inputs in order that values keep inside a extra constant vary. This straightforward thought helps the mannequin study an optimum scale and imply for inputs on the layer degree. Consequently, gradients that circulate backward to replace weights throughout backpropagation achieve this extra easily, lowering uncomfortable side effects like sensitivity to the burden initialization methodology, e.g., He initialization. And most significantly, this mechanism has confirmed to facilitate sooner and extra dependable coaching.
At this level, two typical questions could come up:
- Why the “batch” in batch normalization?: In case you are pretty acquainted with the fundamentals of coaching neural networks, you could know that the coaching set is partitioned into mini-batches — usually containing 32 or 64 situations every — to hurry up and scale the optimization course of underlying coaching. Thus, the method is so named as a result of the imply and variance used for normalization of weighted inputs aren’t calculated over your complete coaching set, however somewhat on the batch degree.
- Can or not it’s utilized to all layers in a neural community?: Batch normalization is often utilized to the hidden layers, which is the place activations can destabilize throughout coaching. Since uncooked inputs are normally normalized beforehand, it’s uncommon to use batch normalization within the enter layer. Likewise, making use of it to the output layer is counterproductive, as it might break the assumptions made for the anticipated vary for the output’s values, particularly as an example in regression neural networks for predicting features like flight costs, rainfall quantities, and so forth.
A serious optimistic impression of batch normalization is a powerful discount within the vanishing gradient downside. It additionally gives extra robustness, reduces sensitivity to the chosen weight initialization methodology, and introduces a regularization impact. This regularization helps fight overfitting, typically eliminating the necessity for different particular methods like dropout.
Easy methods to Implement it in Keras
Keras is a well-liked Python API on prime of TensorFlow used to construct neural community fashions, the place designing the structure is a vital step earlier than coaching. This instance exhibits how easy it’s to implement batch normalization in a easy neural community to be skilled with Keras:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | from tensorflow.keras.fashions import Sequential from tensorflow.keras.layers import Dense, BatchNormalization, Activation from tensorflow.keras.optimizers import Adam
mannequin = Sequential([ Dense(64, input_shape=(20,)), BatchNormalization(), Activation(‘relu’),
Dense(32), BatchNormalization(), Activation(‘relu’),
Dense(1, activation=‘sigmoid’) ])
mannequin.compile(optimizer=Adam(), loss=‘binary_crossentropy’, metrics=[‘accuracy’])
mannequin.abstract() |
Introducing this technique is so simple as including BatchNormalization() between the layer definition and its related activation operate. The enter layer on this instance shouldn’t be explicitly outlined, with the primary dense layer performing as the primary hidden layer that receives pre-normalized uncooked inputs.
Importantly, be aware that incorporating batch normalization forces us to outline every subcomponent within the layer individually, not having the ability to specify the activation operate as an argument contained in the layer definition, e.g., Dense(32, activation='relu'). Nonetheless, conceptually talking, the three strains of code can nonetheless be interpreted as one neural community layer as an alternative of three, though Keras and TensorFlow internally handle them as separate sublayers.
Wrapping Up
This text offered a mild and approachable introduction to batch normalization: a easy but very efficient mechanism that usually helps alleviate some frequent issues discovered when coaching neural community fashions. Easy phrases (or at the least I attempted to!), no math right here and there, and for these a bit extra tech-savvy, a ultimate (additionally light) instance of find out how to implement it in Python.