

On the subject of constructing higher AI, the standard technique is to make fashions larger. However this strategy has a serious downside: it turns into extremely costly.
However, DeepSeek-V3.2-Exp took a unique path…
As a substitute of simply including extra energy, they targeted on working smarter. The result’s a brand new sort of mannequin that delivers top-tier efficiency for a fraction of the associated fee. By introducing their “sparse consideration” mechanism, DeepSeek isn’t simply tweaking the engine; it’s redesigning the gas injection system for unprecedented effectivity.
Let’s break down precisely how they did it.
Highlights of the Replace
- Including Sparse Consideration: The one architectural distinction between the brand new V3.2 mannequin and its predecessor (V3.1) is the introduction of DSA. This exhibits they targeted all their effort on fixing the effectivity downside.
- A “Lightning Indexer”: DSA works through the use of a quick, light-weight part known as a lightning indexer. This indexer shortly scans the textual content and picks out solely crucial phrases for the mannequin to give attention to, ignoring the remainder.
- A Large Complexity Discount: DSA modifications the core computational downside from an exponentially tough one
O(L²)to a a lot less complicated, linear oneO(Lk). That is the mathematical secret behind the large pace and value enhancements. - Constructed for Actual {Hardware}: The success of DSA depends on extremely optimized software program designed to run completely on trendy AI chips (like H800 GPUs). This tight integration between the good algorithm and the {hardware} is what delivers the ultimate, dramatic beneficial properties.
Learn in regards to the Earlier replace right here: Deepseek-V3.1-Terminus!
DeepSeek Sparse Consideration (DSA)
On the coronary heart of each LLM is the “consideration” mechanism: the system that determines how necessary every phrase in a sentence is to each different phrase.
The issue?
Conventional “dense” consideration is wildly inefficient. Its computational price scales quadratically (O(L²)), that means that doubling the textual content size quadruples the computation and value.
DeepSeek Sparse Consideration (DSA) is the answer to this bloat. It doesn’t take a look at the whole lot; it neatly selects what to give attention to. The system consists of two key components:
- The Lightning Indexer: It is a light-weight, high-speed scanner. For any given phrase (a “question token”), it quickly scores all of the previous phrases to find out their relevance. Crucially, this indexer is designed for pace: it makes use of a small variety of heads and may run in FP8 precision, making its computational footprint remarkably small.
- Superb-Grained Token Choice: As soon as the indexer has scored the whole lot, DSA doesn’t simply seize blocks of textual content. It performs a exact, “fine-grained” choice, plucking solely the top-Ok most related tokens from throughout all the doc. The principle consideration mechanism then solely processes this fastidiously chosen, sparse set.
The Consequence: DSA reduces the core consideration complexity from O(L²) to O(Lk), the place ok is a hard and fast variety of chosen tokens. That is the mathematical basis for the large effectivity beneficial properties. Whereas the lightning indexer itself nonetheless has O(L²) complexity, it’s so light-weight that the online impact continues to be a dramatic discount in whole computation.
The Coaching Pipeline: A Two-Stage Tune-Up
You may’t simply slap a brand new consideration mechanism onto a billion-parameter mannequin and hope it really works. DeepSeek employed a meticulous, two-stage coaching course of to combine DSA seamlessly.
- Stage 1: Continued Pre-Coaching (The Heat-Up)
- Dense Heat-up (2.1B tokens): Ranging from the V3.1-Terminus checkpoint, DeepSeek first “warmed up” the brand new lightning indexer. They stored the primary mannequin frozen and ran a brief coaching stage the place the indexer realized to foretell the output of the complete, dense consideration mechanism. This aligned the brand new indexer with the mannequin’s current information.
- Sparse Coaching (943.7B tokens): That is the place the actual magic occurred. After the warm-up, DeepSeek switched on the complete sparse consideration, deciding on the highest 2048 key-value tokens for every question. For the primary time, all the mannequin was skilled to function with this new, selective imaginative and prescient, studying to depend on the sparse choices reasonably than the dense complete.
- Stage 2: Submit-Coaching (The Ending College)
To make sure a good comparability, DeepSeek used the very same post-training pipeline as V3.1-Terminus. This rigorous strategy proves that any efficiency variations are resulting from DSA, not modifications in coaching information.- Specialist Distillation: They created 5 powerhouse specialist fashions (for Math, Coding, Reasoning, Agentic Coding, and Agentic Search) utilizing heavy-duty Reinforcement Studying. The information from these specialists was then distilled into the ultimate V3.2 mannequin.
- Blended RL with GRPO: As a substitute of a multi-stage course of, they used Group Relative Coverage Optimization (GRPO) in a single, blended stage. The reward perform was fastidiously engineered to stability key trade-offs:
- Size vs. Accuracy: Penalizing unnecessarily lengthy solutions.
- Language Consistency vs. Accuracy: Making certain responses remained coherent and human-like.
- Rule-Based mostly & Rubric-Based mostly Rewards: Utilizing automated checks for reasoning/agent duties and tailor-made rubrics for common duties.
The {Hardware} Secret Sauce: Optimized Kernels
An excellent algorithm is ineffective if it runs slowly on precise {hardware}. DeepSeek’s dedication to effectivity shines right here with deeply optimized, open-source code.
The mannequin leverages specialised kernels like FlashMLA, that are custom-built to run the advanced MLA and DSA operations with excessive effectivity on trendy Hopper GPUs (just like the H800). These optimizations are publicly obtainable in pull requests to repositories like DeepGEMM, FlashMLA, and tilelang, permitting the mannequin to realize near-theoretical peak reminiscence bandwidth (as much as 3000 GB/s) and compute efficiency. This hardware-aware design is what transforms the theoretical effectivity of DSA into tangible, real-world pace.
Efficiency & Price – A New Stability
So, what’s the ultimate final result of this engineering marvel? The info reveals a transparent and compelling story.
Price Discount
Probably the most speedy impression is on the underside line. DeepSeek introduced a >50% discount in API pricing. The technical benchmarks are much more putting:
- Inference Pace: 2–3x sooner on lengthy contexts.
- Reminiscence Utilization: 30–40% decrease.
- Coaching Effectivity: 50% sooner.
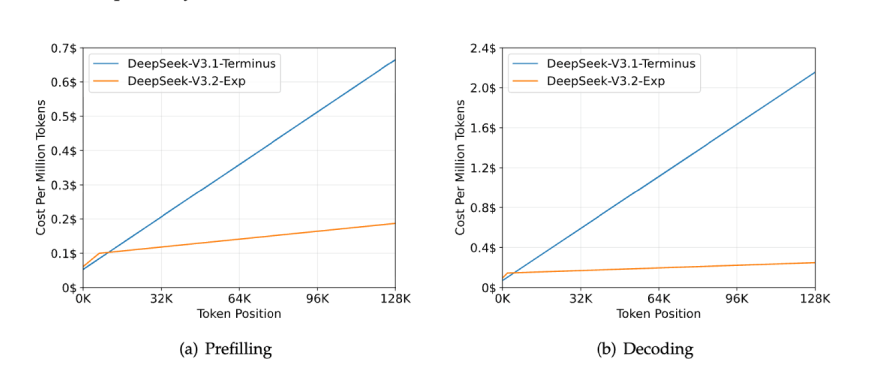
The actual-world inference price for decoding a 128K context window plummets to an estimated $0.25, in comparison with $2.20 for dense consideration, making it 10x cheaper.
Higher Efficiency
On combination, V3.2-Exp maintains efficiency parity with its predecessor. Nevertheless, a more in-depth look reveals a logical trade-off:
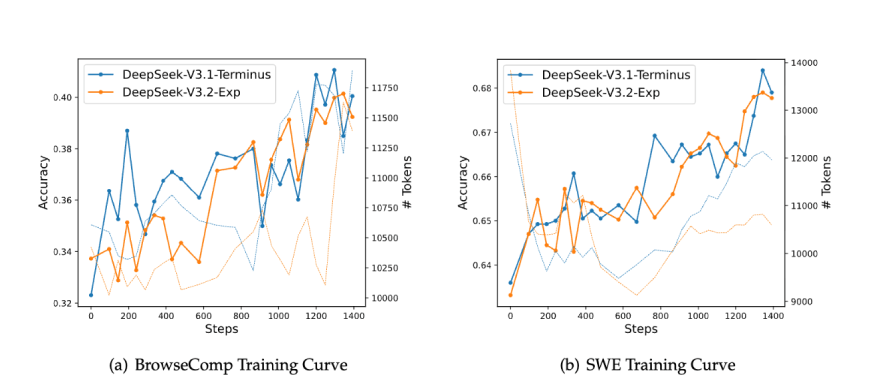
- The Wins: The mannequin exhibits vital beneficial properties in coding (Codeforces) and agentic duties (BrowseComp). This makes good sense: code and tool-use typically include redundant info, and DSA’s capability to filter noise is a direct benefit.
- The Commerce-Offs: There are minor regressions in a number of ultra-complex, summary reasoning benchmarks (like GPQA Diamond and HMMT). The speculation is that these duties depend on connecting very delicate, long-range dependencies that the present DSA masks may sometimes miss.
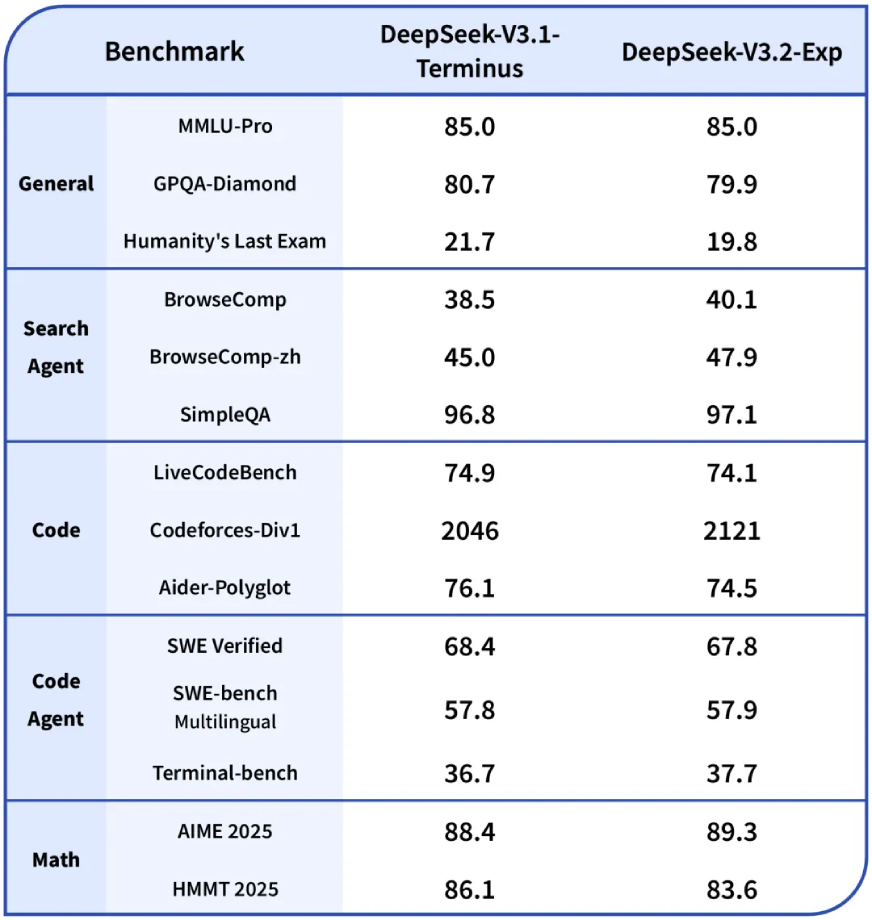
Deepseek-V3.1-Terminus vs DeepSeek-V3.2-Exp
Let’s Attempt the New DeepSeek-V3.2-Exp
The duties I will probably be doing right here will probably be similar as we did in one in every of our earlier articles on Deepseek-V3.1-Terminus. This may assist in figuring out how the brand new replace is healthier.
Job 1: Journey Plan
I must plan a 7-day journey to Kyoto, Japan, for mid-November. The itinerary ought to give attention to conventional tradition, together with temples, gardens, and tea ceremonies. Discover the perfect time to see the autumn leaves, an inventory of three must-visit temples for ‘Momiji’ (autumn leaves), and a highly-rated conventional tea home with English-friendly providers. Additionally, discover a well-reviewed ryokan (conventional Japanese inn) within the Gion district. Set up all the data into a transparent, day-by-day itinerary.
Output:

You may view the complete output right here.
Deepseek-V3.1-Terminus vs DeepSeek-V3.2-Exp Output Comparability
| Characteristic | DeepSeek-V3.1-Terminus | DeepSeek-V3.2-Exp | Winner |
|---|---|---|---|
| Construction & Group | Single steady paragraph | Properly-structured with clear sections and bullet factors | V3.2-Exp |
| Command Presentation | Instructions embedded in operating textual content | Devoted code blocks with correct formatting | V3.2-Exp |
| Completeness & Depth | Primary rationalization solely | Contains sensible examples and use circumstances | V3.2-Exp |
| Newbie Friendliness | Assumes prior information | Explains ideas clearly for newcomers | V3.2-Exp |
Job 2: Coding Agent
I want a Python script that scrapes a public listing of the highest 100 movies of all time from a web site (you’ll be able to select a dependable supply like IMDb, Rotten Tomatoes, or a well known journal’s listing). The script ought to then save the movie titles, launch years, and a quick description for every film right into a JSON file. Embody error dealing with for community points or modifications within the web site’s construction. Are you able to generate the complete script and clarify every step of the method?
Output:
class IMDbTop100Scraper:
def __init__(self):
self.base_url = "
self.headers = {
'Consumer-Agent': 'Mozilla/5.0 (Home windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
self.films = []
def fetch_page(self, url: str) -> Optionally available[BeautifulSoup]:
"""
Fetch the webpage and return BeautifulSoup object.
Handles community errors and retries.
"""
attempt:
response = requests.get(url, headers=self.headers, timeout=10)
response.raise_for_status() # Raises an HTTPError for dangerous responses
# Verify if we obtained a legitimate HTML response
if 'textual content/html' not in response.headers.get('content-type', ''):
elevate ValueError("Obtained non-HTML response")
return BeautifulSoup(response.content material, 'html.parser')
besides requests.exceptions.RequestException as e:
print(f"Community error occurred: {e}")
return None
besides Exception as e:
print(f"Surprising error whereas fetching web page: {e}")
return None
def parse_movie_list(self, soup: BeautifulSoup) -> Record[Dict]:
"""
Parse the primary film listing web page to extract titles and years.
"""
films = []
attempt:
# IMDb's high chart construction - this selector may want updating
movie_elements = soup.choose('li.ipc-metadata-list-summary-item')
if not movie_elements:
# Different selector if the first one fails
movie_elements = soup.choose('.cli-children')
if not movie_elements:
elevate ValueError("Couldn't discover film parts on the web page")
for component in movie_elements[:100]: # Restrict to high 100
movie_data = self.extract_movie_data(component)
if movie_data:
films.append(movie_data)
besides Exception as e:
print(f"Error parsing film listing: {e}")
return filmsDiscover full code right here.
Deepseek-V3.1-Terminus vs DeepSeek-V3.2-Exp Output Comparability
| Characteristic | DeepSeek-V3.1-Terminus | DeepSeek-V3.2-Exp | Winner |
|---|---|---|---|
| Construction & Presentation | Single dense paragraph | Clear headings, bullet factors, abstract desk | V3.2-Exp |
| Security & Consumer Steerage | No security warnings | Daring warning about unstaged modifications loss | V3.2-Exp |
| Completeness & Context | Primary two strategies solely | Provides legacy `git checkout` methodology and abstract desk | V3.2-Exp |
| Actionability | Instructions embedded in textual content | Devoted command blocks with express flag explanations | V3.2-Exp |
Additionally Learn: Evolution of DeepSeek: The way it Turned a World AI Recreation-Changer!
Conclusion
DeepSeek-V3.2-Exp is greater than a mannequin; it’s a press release. It proves that the subsequent nice leap in AI gained’t essentially be a leap in uncooked energy, however a leap in effectivity. By surgically attacking the computational waste in conventional transformers, DeepSeek has made long-context, high-volume AI functions financially viable for a wider market.
The “Experimental” tag is a candid admission that it is a work in progress, notably in balancing efficiency throughout all duties. However for the overwhelming majority of enterprise use circumstances, the place processing complete codebases, authorized paperwork, and datasets is the objective. DeepSeek hasn’t simply launched a brand new mannequin; it has began a brand new race.
To know extra in regards to the mannequin, checkout this hyperlink.
![]()
Good day, I’m Nitika, a tech-savvy Content material Creator and Marketer. Creativity and studying new issues come naturally to me. I’ve experience in creating result-driven content material methods. I’m nicely versed in search engine marketing Administration, Key phrase Operations, Net Content material Writing, Communication, Content material Technique, Modifying, and Writing.
Login to proceed studying and luxuriate in expert-curated content material.