
Each week, new fashions are launched, together with dozens of benchmarks. However what does that imply for a practitioner deciding which mannequin to make use of? How ought to they strategy assessing the standard of a newly launched mannequin? And the way do benchmarked capabilities like reasoning translate into real-world worth?
On this submit, we’ll consider the newly launched NVIDIA Llama Nemotron Tremendous 49B 1.5 mannequin. We use syftr, our generative AI workflow exploration and analysis framework, to floor the evaluation in an actual enterprise drawback and discover the tradeoffs of a multi-objective evaluation.
After inspecting greater than a thousand workflows, we provide actionable steering on the use circumstances the place the mannequin shines.
The variety of parameters depend, however they’re not every part
It ought to be no shock that parameter depend drives a lot of the price of serving LLMs. Weights must be loaded into reminiscence, and key-value (KV) matrices cached. Larger fashions usually carry out higher — frontier fashions are virtually all the time large. GPU developments have been foundational to AI’s rise by enabling these more and more giant fashions.
However scale alone doesn’t assure efficiency.
Newer generations of fashions typically outperform their bigger predecessors, even on the similar parameter depend. The Nemotron fashions from NVIDIA are an excellent instance. The fashions construct on present open fashions, , pruning pointless parameters, and distilling new capabilities.
Which means a smaller Nemotron mannequin can typically outperform its bigger predecessor throughout a number of dimensions: sooner inference, decrease reminiscence use, and stronger reasoning.
We needed to quantify these tradeoffs — particularly towards among the largest fashions within the present technology.
How rather more correct? How rather more environment friendly? So, we loaded them onto our cluster and started working.
How we assessed accuracy and price
Step 1: Determine the issue
With fashions in hand, we wanted a real-world problem. One which assessments reasoning, comprehension, and efficiency inside an agentic AI circulation.
Image a junior monetary analyst making an attempt to ramp up on an organization. They need to be capable of reply questions like: “Does Boeing have an bettering gross margin profile as of FY2022?”
However in addition they want to elucidate the relevance of that metric: “If gross margin is just not a helpful metric, clarify why.”
To check our fashions, we’ll assign it the duty of synthesizing information delivered by an agentic AI circulation after which measure their capacity to effectively ship an correct reply.
To reply each forms of questions appropriately, the fashions must:
- Pull information from a number of monetary paperwork (equivalent to annual and quarterly stories)
- Examine and interpret figures throughout time durations
- Synthesize an evidence grounded in context
FinanceBench benchmark is designed for precisely one of these job. It pairs filings with expert-validated Q&A, making it a powerful proxy for actual enterprise workflows. That’s the testbed we used.
Step 2: Fashions to workflows
To check in a context like this, you must construct and perceive the total workflow — not simply the immediate — so you possibly can feed the suitable context into the mannequin.
And it’s important to do that each time you consider a brand new mannequin–workflow pair.
With syftr, we’re capable of run tons of of workflows throughout completely different fashions, rapidly surfacing tradeoffs. The result’s a set of Pareto-optimal flows just like the one proven under.

Within the decrease left, you’ll see easy pipelines utilizing one other mannequin because the synthesizing LLM. These are cheap to run, however their accuracy is poor.
Within the higher proper are essentially the most correct — however extra costly since these usually depend on agentic methods that break down the query, make a number of LLM calls, and analyze every chunk independently. Because of this reasoning requires environment friendly computing and optimizations to maintain inference prices in verify.
Nemotron reveals up strongly right here, holding its personal throughout the remaining Pareto frontier.
Step 3: Deep dive
To higher perceive mannequin efficiency, we grouped workflows by the LLM used at every step and plotted the Pareto frontier for every.
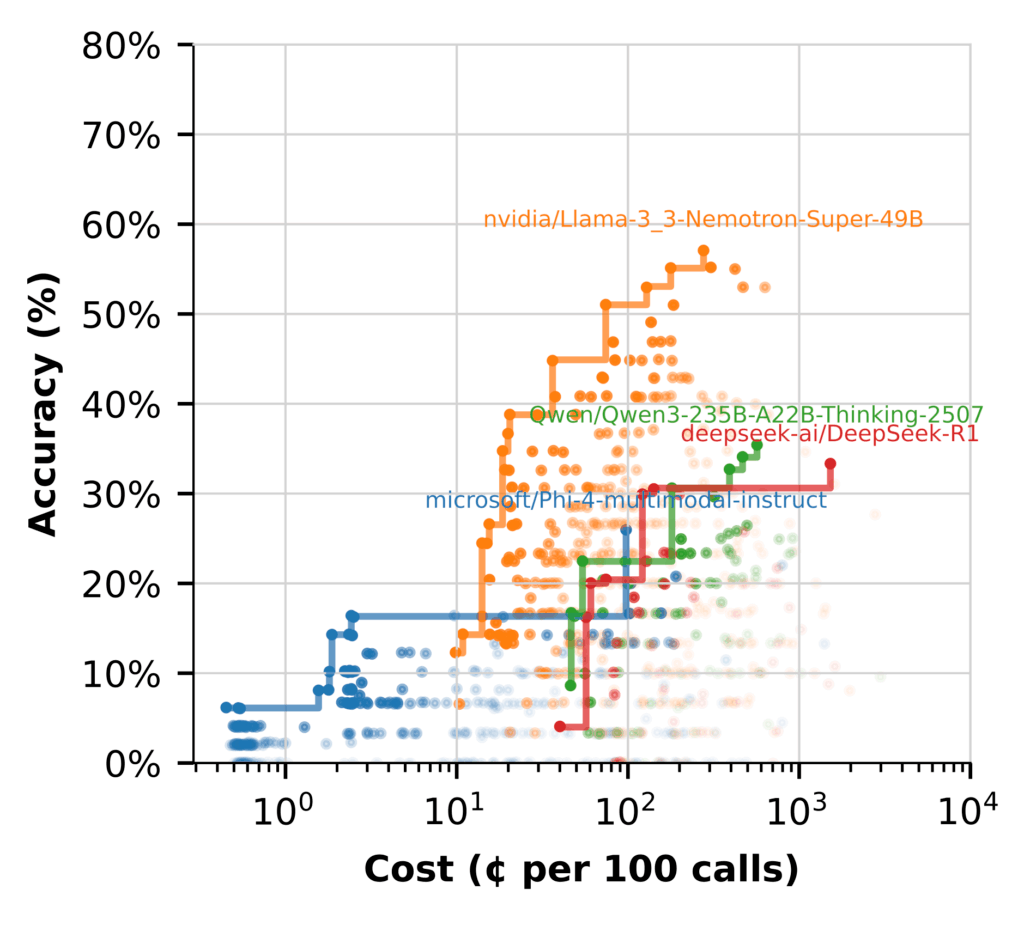
The efficiency hole is evident. Most fashions battle to get anyplace close to Nemotron’s efficiency. Some have bother producing affordable solutions with out heavy context engineering. Even then, it stays much less correct and costlier than bigger fashions.
However after we swap to utilizing the LLM for (Hypothetical Doc Embeddings) HyDE, the story modifications. (Flows marked N/A don’t embrace HyDE.)
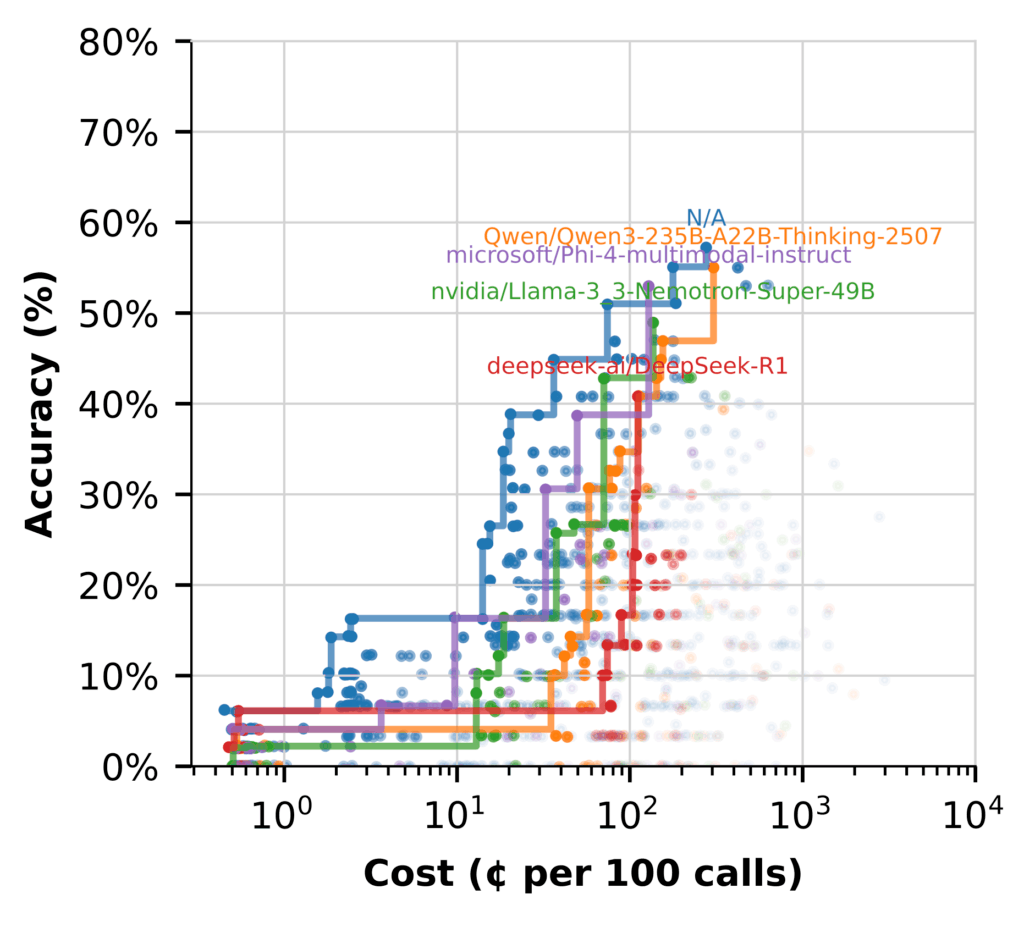
Right here, a number of fashions carry out properly, with affordability whereas delivering excessive‑accuracy flows.
Key takeaways:
- Nemotron shines in synthesis, producing excessive‑constancy solutions with out added price
- Utilizing different fashions that excel at HyDE frees Nemotron to give attention to high-value reasoning
- Hybrid flows are essentially the most environment friendly setup, utilizing every mannequin the place it performs greatest
Optimizing for worth, not simply measurement
When evaluating new fashions, success isn’t nearly accuracy. It’s about discovering the suitable stability of high quality, price, and match to your workflow. Measuring latency, effectivity, and total influence helps make sure you’re getting actual worth
NVIDIA Nemotron fashions are constructed with this in thoughts. They’re designed not just for energy, however for sensible efficiency that helps groups drive influence with out runaway prices.
Pair that with a structured, Syftr-guided analysis course of, and also you’ve obtained a repeatable approach to keep forward of mannequin churn whereas retaining compute and finances in verify.
To discover syftr additional, take a look at the GitHub repository.